- Flowfiles--are objects that represent a piece of data as well as metadata about the object.
- Processors--do the work of transforming and manipulating the data. They are similar to bolts in Storm.
- Connections--are the linkages between the processors that facilitate what kind of data (e.g., failed, matched) should move to the next processor.
- NiFi Canvas--is the graph-paper like interface of the NiFi GUI.
 NiFi has a simple but effective GUI that streamlines the user’s interaction with NiFi. Users can build the data flow and monitor any errors as well as message processing metrics.
NIFI Data Flow
To get started, we will build a small data flow that gets messages from a Kafka topic and persists the messages to your hard drive. We will use NiFi's pre-built GetKafka and PutFile processors to create our data flow. NiFi’s extensive pre-built processor list eases linking your NiFi dataflow to external services, such as AWS, Kafka, ElasticSearch, etc.
Building Your First Flow
To add a processor to the NiFi canvas:
Click on the processor symbol with the "plus sign"on the menu and drag it to the canvas.
Search for the type of processor, highlight the process, and click add to add the processor to the canvas. We will be adding the GetKafka processor for this example.
NiFi has a simple but effective GUI that streamlines the user’s interaction with NiFi. Users can build the data flow and monitor any errors as well as message processing metrics.
NIFI Data Flow
To get started, we will build a small data flow that gets messages from a Kafka topic and persists the messages to your hard drive. We will use NiFi's pre-built GetKafka and PutFile processors to create our data flow. NiFi’s extensive pre-built processor list eases linking your NiFi dataflow to external services, such as AWS, Kafka, ElasticSearch, etc.
Building Your First Flow
To add a processor to the NiFi canvas:
Click on the processor symbol with the "plus sign"on the menu and drag it to the canvas.
Search for the type of processor, highlight the process, and click add to add the processor to the canvas. We will be adding the GetKafka processor for this example. 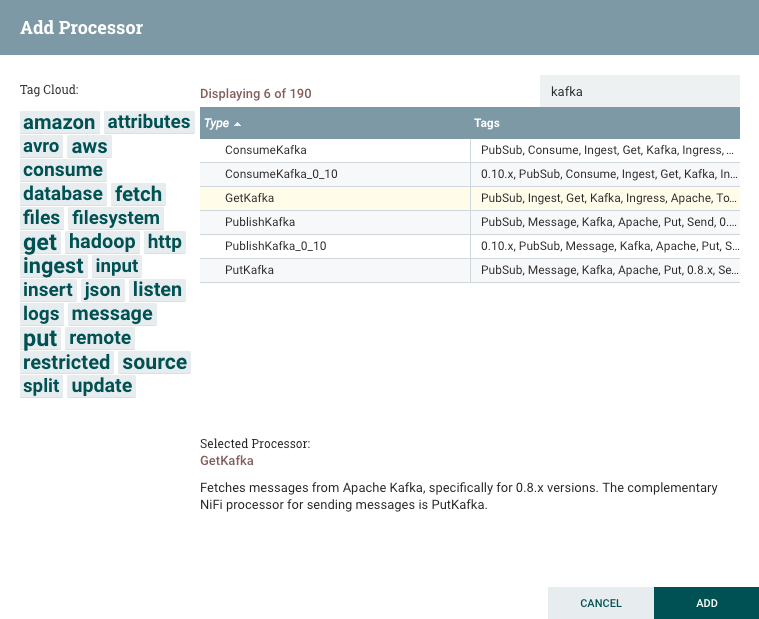 Right-click on the processor and click on the Configure option in the menu to customize the processor as necessary. For the GetKafka Processor, we will add a Topic Name and a ZooKeeper Connection String.
Right-click on the processor and click on the Configure option in the menu to customize the processor as necessary. For the GetKafka Processor, we will add a Topic Name and a ZooKeeper Connection String. 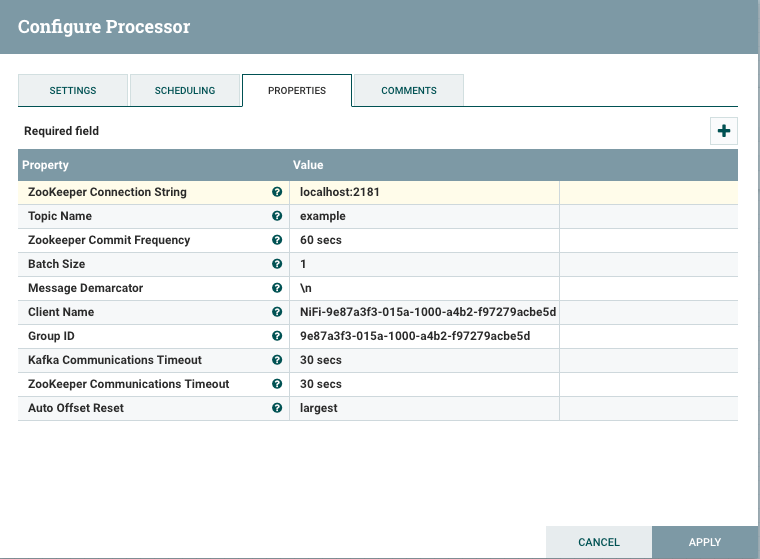 Repeat the same steps to add the PutFile processor.
Repeat the same steps to add the PutFile processor.  Add a connection between the two processors by hovering the mouse in the middle of the GetKafka processors until the arrow symbol is visible, then drag the symbol to the PutFile processor. In the above image, the connection is named “success.” This means that only successful flowfiles flow to the PutFile processor. The GetKafka processor does not have an option for failed flowfiles (as that would mean there is no flowfile), but other processors do, so it will be up to the user to determine how to manage successful and failed flowfile connections between processors. For example, a user could route a failed flowfile to a logger processor to log any failures while routing successful flowfiles to another processor for further processing.
Add a connection between the two processors by hovering the mouse in the middle of the GetKafka processors until the arrow symbol is visible, then drag the symbol to the PutFile processor. In the above image, the connection is named “success.” This means that only successful flowfiles flow to the PutFile processor. The GetKafka processor does not have an option for failed flowfiles (as that would mean there is no flowfile), but other processors do, so it will be up to the user to determine how to manage successful and failed flowfile connections between processors. For example, a user could route a failed flowfile to a logger processor to log any failures while routing successful flowfiles to another processor for further processing.  In addition, a processor can be set to automatically terminate relationships. For example, a failed flowfile can be automatically terminated in a processor, so that it will not reach the next processor in the dataflow. This is done in the settings tab on any processor. All flowfiles at the end of a process flow (i.e., flowfiles that reach the final processor) will need to be terminated as there will be no more processors left to process the flowfile. Since the PutFile processor, is the last processor in our flow, we will terminate failure and success relationships.
In addition, a processor can be set to automatically terminate relationships. For example, a failed flowfile can be automatically terminated in a processor, so that it will not reach the next processor in the dataflow. This is done in the settings tab on any processor. All flowfiles at the end of a process flow (i.e., flowfiles that reach the final processor) will need to be terminated as there will be no more processors left to process the flowfile. Since the PutFile processor, is the last processor in our flow, we will terminate failure and success relationships.
 Building Custom NiFi Functionality
Building Custom NiFi Functionality
 Now that you have created your first basic dataflow, you are ready to explore adding more processors and creating more complex functionality using the plethora of pre-existing processors provided by NiFi. However, if a functionality is desired that is not currently available as a pre-built processor, we can also create our own processors. When creating custom processors, it is recommended that each processor perform one specific function. For example, above is the code for creating a processor that outputs a random hexadecimal hash as a NiFi flowfile attribute. There is a NiFi Mockito library that is also available to write tests for the customized processors. Adding the customized processors simply requires creating a nar file and dropping it in the ${NIFI_HOME}/lib folder.
Here is how the HexHash Processor code translates:
Now that you have created your first basic dataflow, you are ready to explore adding more processors and creating more complex functionality using the plethora of pre-existing processors provided by NiFi. However, if a functionality is desired that is not currently available as a pre-built processor, we can also create our own processors. When creating custom processors, it is recommended that each processor perform one specific function. For example, above is the code for creating a processor that outputs a random hexadecimal hash as a NiFi flowfile attribute. There is a NiFi Mockito library that is also available to write tests for the customized processors. Adding the customized processors simply requires creating a nar file and dropping it in the ${NIFI_HOME}/lib folder.
Here is how the HexHash Processor code translates:
 And with the code below “hexHash” attribute is added to NiFi flowfiles:
And with the code below “hexHash” attribute is added to NiFi flowfiles:

 To deploy the newly created processor, create a nar (essentially a jar file but for NiFi) of your Java code. If using maven, use “mvn clean package” to create a nar file. Then, stop NiFi using the command “${NIFI_HOME}/nifi.sh stop” and drop the nar file in the {$NIFI_HOME}/lib folder. When NiFi is restarted using the command “${NIFI_HOME}/nifi.sh start”, the processor will be available in the NiFi GUI. When stopping a NiFi flow or a processor, you don’t have to worry about losing data as the data that has not been processed yet is queued in the connector so that it is available for processing the next time the processor is started.
NiFi on a Multi-Node Cluster
Deploying NiFi on a multi-node cluster involves a few more steps than a single node deployment. Since release 1.0.0, NiFi has zero master clustering. Consequently, in the latest release of NiFi instead of having a cluster manager, the cluster auto-elects the leader node, which provides fault tolerance in case of a failing leader node. The NiFi nodes communicate with each other through ZooKeeper and a cluster deployment requires configuration changes to the nifi.properties and zookeeper.properties files. Even in a multi-node cluster, changes made in the GUI canvas to the dataflow are applied across all the other nodes and the web GUI continues to provide statistics on the dataflows across all nodes. The dataflows are saved in the data.flow.gz file, which is replicated across all the nodes and the web GUI can be accessed using the IP address of any of the nodes.
To deploy the newly created processor, create a nar (essentially a jar file but for NiFi) of your Java code. If using maven, use “mvn clean package” to create a nar file. Then, stop NiFi using the command “${NIFI_HOME}/nifi.sh stop” and drop the nar file in the {$NIFI_HOME}/lib folder. When NiFi is restarted using the command “${NIFI_HOME}/nifi.sh start”, the processor will be available in the NiFi GUI. When stopping a NiFi flow or a processor, you don’t have to worry about losing data as the data that has not been processed yet is queued in the connector so that it is available for processing the next time the processor is started.
NiFi on a Multi-Node Cluster
Deploying NiFi on a multi-node cluster involves a few more steps than a single node deployment. Since release 1.0.0, NiFi has zero master clustering. Consequently, in the latest release of NiFi instead of having a cluster manager, the cluster auto-elects the leader node, which provides fault tolerance in case of a failing leader node. The NiFi nodes communicate with each other through ZooKeeper and a cluster deployment requires configuration changes to the nifi.properties and zookeeper.properties files. Even in a multi-node cluster, changes made in the GUI canvas to the dataflow are applied across all the other nodes and the web GUI continues to provide statistics on the dataflows across all nodes. The dataflows are saved in the data.flow.gz file, which is replicated across all the nodes and the web GUI can be accessed using the IP address of any of the nodes.
 Pitfalls
Since NiFi allows multiple data flows to run concurrently, simply replicating a design used in other data processing tools may not translate well in NiFi. For example, if several parallel flows with similar functionality are created, each time a change needs to be made to a processor, flowfile, or connection used in multiple places, the change will need to be replicated repeatedly, which can become tedious depending on the complexity of your flow. As such, it is recommended that you rethink your dataflow design through the prism of NiFi functionality.
Why NiFi?
In our use case of data transformation and processing, we were deciding between using NiFi or Storm. In the end, we preferred NiFi and here is why: Much of our data processing requires data ingress and egress functionality, which NiFi’s extensive library of pre-built processors markedly simplified. We can simply select and drop into our canvas a processor that could be used to get tweets or Kafka messages and output them to a hard drive or ElasticSearch. In addition, NiFi’s interactive GUI produces an effective mechanism for creating data flows quickly by connecting processors, which is a marked departure from the more laborious process of creating spouts and bolts in Storm. We found deploying NiFi on a cluster to also be a simpler process than Storm. Like Storm, NiFi is fault tolerant on a cluster. But unlike Storm, which has a Nimbus node that deploys the topology and Supervisor nodes that manage the worker processes, all NiFi nodes have similar configurations and provide fault tolerance by auto-electing a leader from any of the available nodes. Overall, NiFi’s out-of-the-box functionality and ease of deployment on a cluster make it a great tool for much of our data processing needs.
Pitfalls
Since NiFi allows multiple data flows to run concurrently, simply replicating a design used in other data processing tools may not translate well in NiFi. For example, if several parallel flows with similar functionality are created, each time a change needs to be made to a processor, flowfile, or connection used in multiple places, the change will need to be replicated repeatedly, which can become tedious depending on the complexity of your flow. As such, it is recommended that you rethink your dataflow design through the prism of NiFi functionality.
Why NiFi?
In our use case of data transformation and processing, we were deciding between using NiFi or Storm. In the end, we preferred NiFi and here is why: Much of our data processing requires data ingress and egress functionality, which NiFi’s extensive library of pre-built processors markedly simplified. We can simply select and drop into our canvas a processor that could be used to get tweets or Kafka messages and output them to a hard drive or ElasticSearch. In addition, NiFi’s interactive GUI produces an effective mechanism for creating data flows quickly by connecting processors, which is a marked departure from the more laborious process of creating spouts and bolts in Storm. We found deploying NiFi on a cluster to also be a simpler process than Storm. Like Storm, NiFi is fault tolerant on a cluster. But unlike Storm, which has a Nimbus node that deploys the topology and Supervisor nodes that manage the worker processes, all NiFi nodes have similar configurations and provide fault tolerance by auto-electing a leader from any of the available nodes. Overall, NiFi’s out-of-the-box functionality and ease of deployment on a cluster make it a great tool for much of our data processing needs.